
A Pinterest mérnökei egy új, CDC-alapú keretrendszerrel váltották le a nehézkes batch-folyamatokat, drasztikusan csökkentve a késleltetést és az infrastruktúra költségeit.
A modern adatközpontú szolgáltatásoknál az adatok frissessége kritikus üzleti tényező. A Pinterestnél a korábbi, batch-alapú (kötegelt) adatbeviteli folyamatok már nem tudták kiszolgálni a gépi tanulási (ML) modellek és az analitikai rendszerek igényeit. A legacy infrastruktúra egyik legnagyobb bottleneckje a 24 órát is meghaladó késleltetés volt, amit egy teljesen új, Change Data Capture (CDC) alapú keretrendszerrel sikerült 15 percre redukálni.
A legacy rendszer korlátai: Miért nem elég a Batch?
A Pinterest korábbi megoldása teljes táblás batch-munkákra épült. Ez mérnöki szempontból több sebből vérzett:
1. Erőforrás-pazarlás: Annak ellenére, hogy a táblák rekordjainak átlagosan csupán 5%-a változott naponta, a rendszer minden alkalommal a teljes adathalmazt újra feldolgozta.
2. Késleltetés: Az adatok elérhetősége gyakran több mint egy napot csúszott, ami ellehetetlenítette a valós idejű termékfunkciókat.
3. Törlések kezelése: A sor szintű törlések (row-level deletions) natív támogatása hiányzott, ami adatkonzisztencia-problémákhoz vezetett.
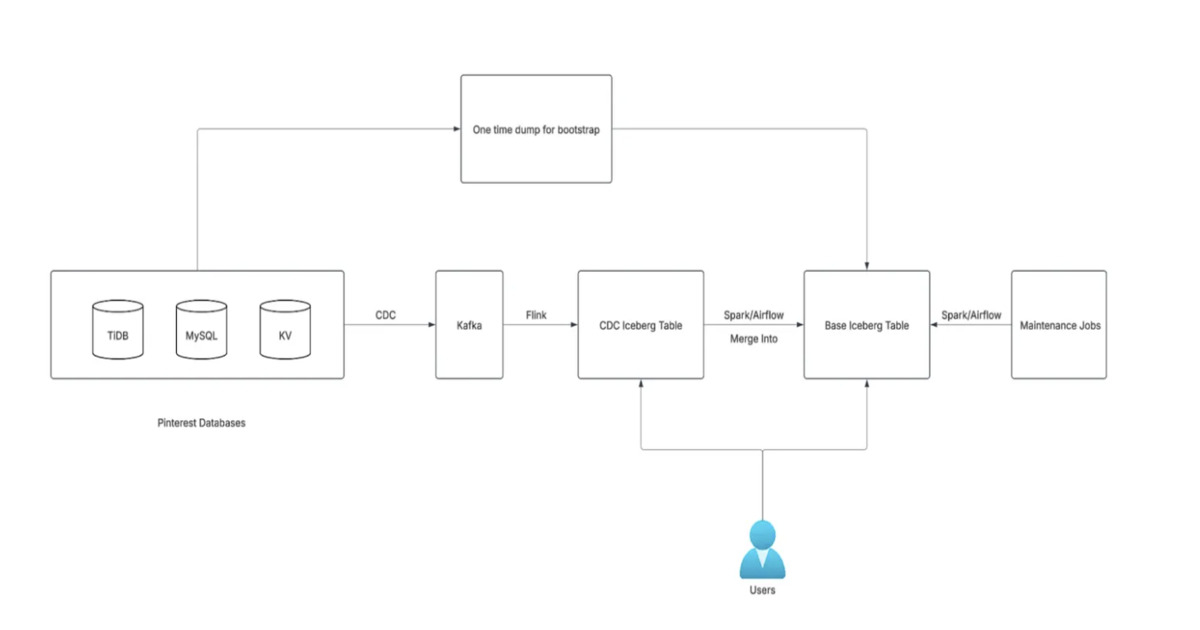
Az új architektúra: CDC, Kafka és Iceberg
Az új keretrendszer alapja a Change Data Capture (CDC) technológia. Ahelyett, hogy periodikusan lekérdeznék a teljes adatbázist, a rendszer a tranzakciós logokból (pl. MySQL binlog) olvassa ki a változásokat (INSERT, UPDATE, DELETE) szinte valós időben.
A technológiai stacket a következő komponensek alkotják:
* Ingestion: Debezium és TiCDC a változások kinyeréséhez.
* Üzenetküldés: Apache Kafka mint elosztott log-buffer.
* Feldolgozás: Apache Flink a streaming adatokhoz és Apache Spark a Merge műveletekhez.
* Tárolás: Apache Iceberg táblaformátum AWS S3-on.
A Merge on Read (MOR) stratégia előnyei
Az Apache Iceberg két fő stratégiát kínál az adatok frissítésére: Copy on Write (COW) és Merge on Read (MOR). A Pinterest mérnökei alapos tesztelés után a MOR mellett döntöttek.
“A Copy on Write stratégia minden frissítésnél újraírta volna a teljes adatfájlokat, ami petabájtos skálán elviselhetetlen tárolási és számítási költségeket generált volna.”
A MOR ezzel szemben a változásokat különálló „delete” és „data” fájlokba írja, és csak olvasáskor egyesíti őket. Ez jelentősen csökkenti a write amplification jelenséget, és lehetővé teszi a 15 perces frissítési ciklusokat.
Optimalizációs technikák a motorháztető alatt
A rendszer teljesítményét több finomhangolással fokozták:
* Iceberg Bucketing: A bázistáblákat az elsődleges kulcs (Primary Key) hash-értéke alapján particionálták. Ez lehetővé teszi a Spark számára, hogy párhuzamosítsa az upsert műveleteket és minimalizálja a szkennelt adatok mennyiségét.
* Small Files Problem: A streaming jellegű írás gyakran sok apró fájlt eredményez, ami rontja a HDFS/S3 teljesítményét. A keretrendszer automatikus tömörítési (compaction) feladatokat futtat a háttérben.
* At-least-once delivery: A Kafka és Flink integráció garantálja, hogy egyetlen változás sem vész el, még rendszerhiba esetén sem.
Mérnöki eredmények és benchmark adatok
Az átállás eredményei magukért beszélnek:
| Metrika | Legacy Batch Rendszer | Új CDC Keretrendszer |
|---|---|---|
| Adat késleltetés (Latency) | 24+ óra | 15 - 60 perc |
| Feldolgozott adatmennyiség | 100% (teljes tábla) | ~5% (csak változások) |
| Erőforrás hatékonyság | Alacsony | Magas (költségcsökkenés) |
| Skálázhatóság | Korlátozott | Petabájtos skála |
Implementációs tanulságok
A Pinterest példája mutatja, hogy a modern adatarchitektúrákban a batch és streaming közötti határ elmosódik. Az Apache Iceberg MOR képességei kulcsfontosságúak voltak abban, hogy a rendszer gazdaságosan üzemeltethető maradjon. Ipari környezetben a CDC bevezetése nemcsak a sebességet növeli, hanem drasztikusan csökkenti az upstream adatbázisok terhelését is, mivel nincs szükség többé erőforrás-igényes full-table scanekre.
A jövőbeli fejlesztések fókuszában az automatizált séma-evolúció (schema evolution) áll, amely lehetővé teszi, hogy az adatbázis-struktúra változásai automatikusan és biztonságosan propagálódjanak a downstream adatfolyamokba.




